
Summary
Both tools shipped major upgrades through May 2026. Claude Opus 4.8 (May 28) leads SWE-bench Pro at 69.2% vs GPT-5.5's 58.6%. GPT-5.5 leads Terminal-Bench and SWE-bench Verified by 0.1 point (88.7% vs 88.6%). Claude leads on Pro and the Verified gap has essentially closed. The real question is still the same: isolated speed (Codex) or coordinated depth (Claude), and what that costs in tokens.
| Dimension | OpenAI Codex (GPT-5.5) | Claude Code (Opus 4.8) |
|---|---|---|
| SWE-bench Pro | 58.6% | 69.2% |
| SWE-bench Verified | 88.7% | 88.6% |
| Terminal-Bench 2.0 | 82.7% | 69.4% |
| CursorBench | Not reported | 70% |
| Context window | 200K tokens | 1M tokens |
| Multi-agent model | Subagents GA (8 parallel) | Agent Teams (coordinated) |
| $20/mo limits | Plus: more sessions/5hr | Pro: hits caps faster |
| GitHub commits/day | Not disclosed | 326K+ (~10% of all public) |
| Open source | Apache-2.0, 91K stars | Proprietary, 132K stars |
| Latest model | GPT-5.5 (April 23, 2026) | Opus 4.8 (May 28, 2026) |
SWE-bench Pro Accuracy (June 2026)
Claude Opus 4.8 leads on Pro
Source: SWE-bench Pro public leaderboard, June 2026
Terminal-Bench 2.0 Score (June 2026)
GPT-5.5 widens the terminal gap
Source: Terminal-Bench 2.0, June 2026
Quick Decision Matrix
- Choose Codex if: You want terminal-first workflows (82.7% Terminal-Bench), subagent parallelism with up to 8 workers, goals/memories for long-running projects, or generous limits on the $20 tier
- Choose Claude Code if: You need coordinated agent teams with messaging and dependency tracking, SWE-bench Pro accuracy (69.2%), 1M token context, or the agent view dashboard for session management
- Choose both if: You want Codex for speed + Claude's agent teams for complex orchestration
Benchmark Warning
SWE-bench Verified and SWE-bench Pro are different benchmark variants with different problem sets. GPT-5.5 leads Verified by 0.1 point (88.7% vs 88.6%). Claude Opus 4.8 leads Pro (69.2% vs 58.6%). Direct score comparison across them is not valid. We show both, plus Terminal-Bench 2.0 and CursorBench, for a fuller picture.
The Architectural Shift
Both tools now have GA multi-agent workflows. Codex shipped subagents GA on March 14 with a manager-worker model (up to 8 parallel agents). Claude Code's Agent Teams use coordinated sub-agents with shared task lists and direct messaging. Both support goals (persistent objectives across sessions), memories (cross-session context), and plugin ecosystems with hooks. The "dedicated context window per subtask" pattern is now standard in both tools.
Token Usage: Claude Code vs Codex on Identical Tasks
Claude uses 3-4x more tokens but produces more thorough output
Source: Independent benchmark by community testers, Feb 2026. Claude's higher token count correlates with more deterministic, thorough outputs.
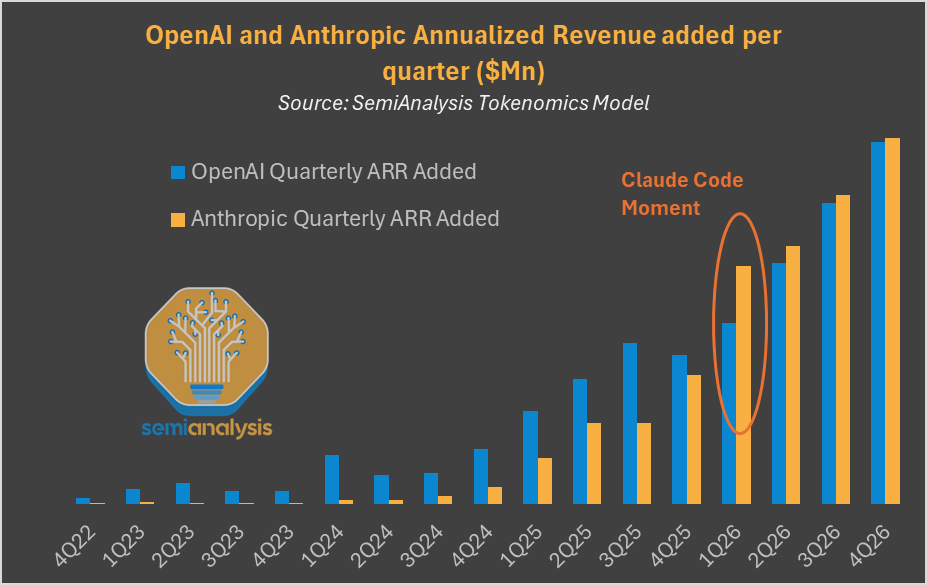
Source: SemiAnalysis Tokenomics Model. Anthropic's quarterly ARR growth accelerated sharply at the "Claude Code Moment" in Q1 2026.
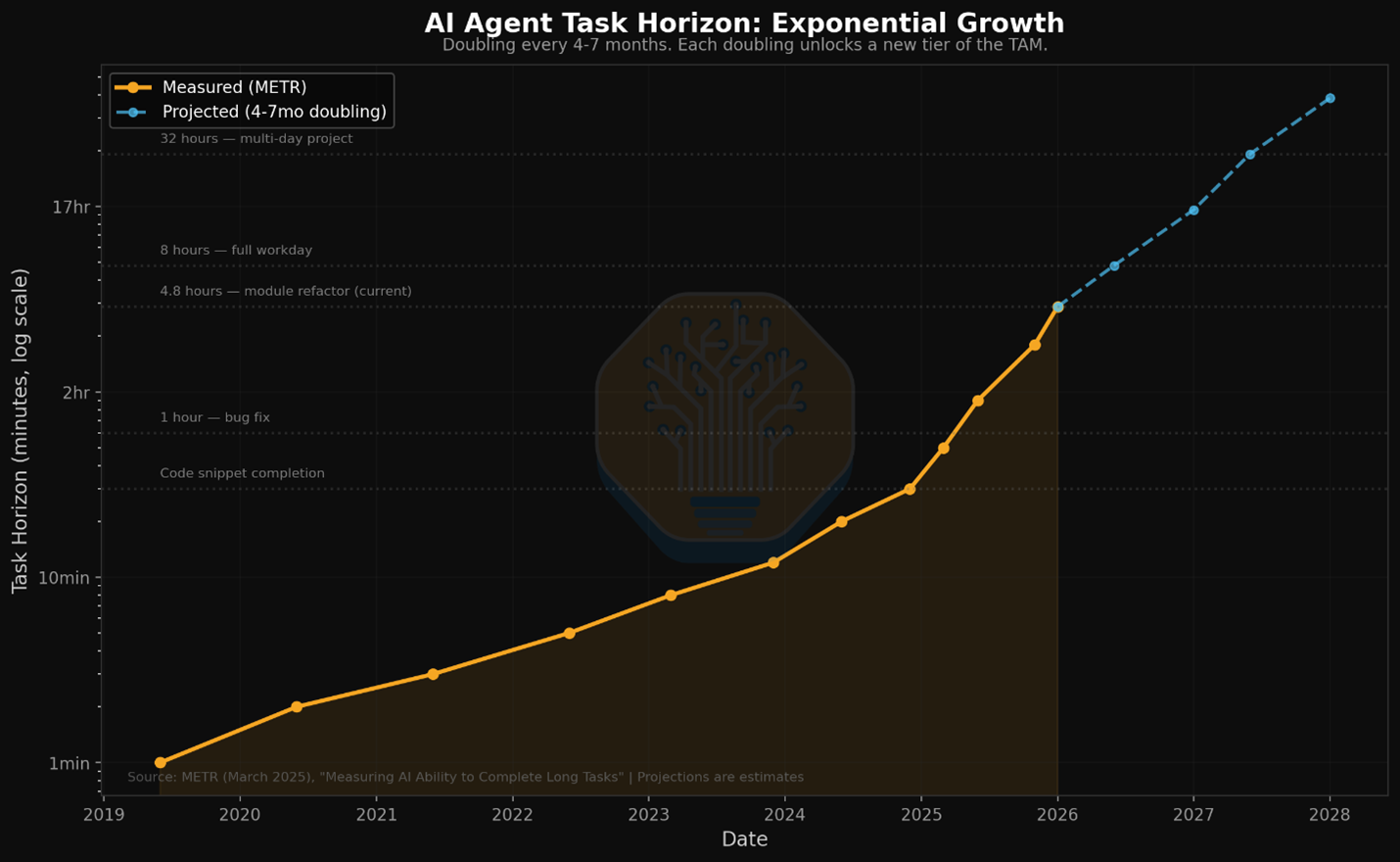
Source: METR / SemiAnalysis. AI agent task horizons are doubling every 4-7 months.
Stat Comparison
Synthetic benchmarks tell part of the story. These 5-bar ratings reflect daily workflow impact across speed, autonomy, consistency, subagent support, and limit generosity.
OpenAI Codex
Speed + subagents GA with 8 parallel workers
"Maximum velocity with subagents GA and persistent goals."
Claude Code
Coordinated agent teams + agent view dashboard
"Best-in-class subagent coordination with agent view dashboard."
GitHub and Marketplace Stats (June 2026)
Claude Code
- 132,000 GitHub stars (up from 71.5K in Feb)
- v2.1.185 (June 20, 2026), ships multiple releases/day
- VS Code: 2M+ installs
- Opus 4.8 default since May 28, 2026
- ~326K GitHub commits/day (~10% of all public commits)
OpenAI Codex
- 91,000 GitHub stars (up from 62.4K in Feb)
- v0.139.0 (June 9, 2026), 800+ releases total
- Codex App: macOS + Windows, Chrome extension (May 7)
- Rust-native CLI, GPT-5.5 support (April 23)
- Subagents GA (March 14): up to 8 parallel workers
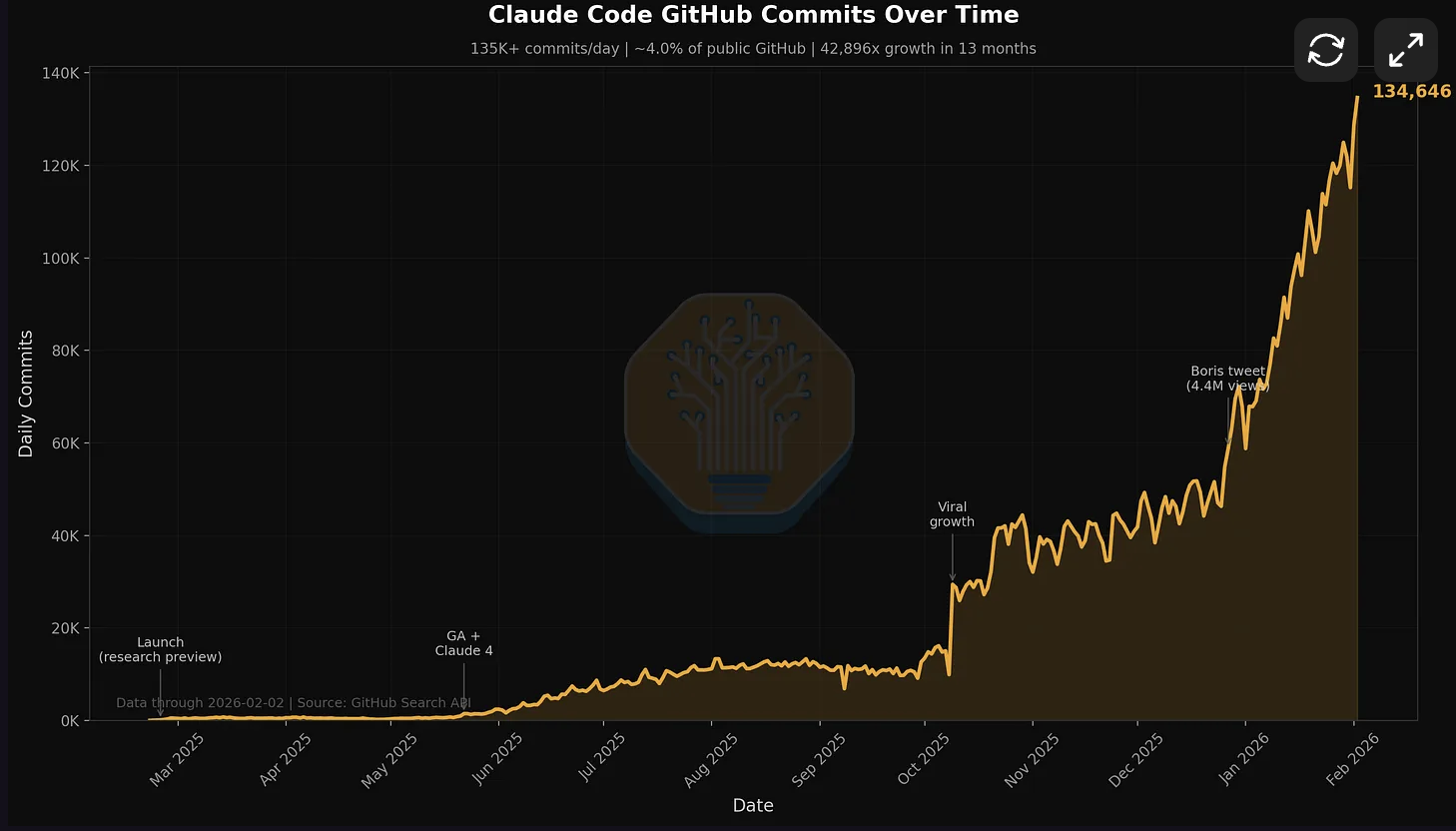
Source: SemiAnalysis / GitHub Search API. Claude Code now accounts for ~10% of all public GitHub commits, up from 4% in February.
Reading the Stats
Codex optimizes for speed and autonomy at the cost of consistency. Claude Code optimizes for consistency and orchestration at the cost of limits. Neither dominates across all dimensions. Both have shipped significant improvements since February: Codex got subagents GA, goals, and memories. Claude Code got Opus 4.8, the agent view dashboard, and effort levels.
Subagent Architecture: How Each Tool Isolates Context
Both Codex and Claude Code now have production-ready multi-agent support. Codex shipped subagents to GA on March 14, 2026. Claude Code's Agent Teams continue to evolve with the new agent view dashboard (v2.1.139). A dedicated context window per task is now standard in both tools, but they implement it in fundamentally different ways.
Why Subagents Matter
The single biggest limitation of AI coding agents is context window pollution. You ask the agent to refactor authentication, it reads 40 files, and by the time it gets to the last file it has forgotten the patterns from the first. Subagents solve this by giving each subtask its own dedicated context window. The auth refactor agent does not share context with the test-writing agent. Each one focuses.
| Aspect | Codex (June 2026) | Claude Code (June 2026) |
|---|---|---|
| Multi-agent model | Subagents GA: manager + explorer/worker/default agents | Agent Teams: coordinated sub-agents with messaging |
| Isolation model | Cloud sandbox per task (container) | Git worktree per agent (local) |
| Max parallel agents | 8 per developer | No hard limit (burns limits per agent) |
| Task coordination | Manager decomposes and collects results | Shared task list with dependency tracking |
| Agent communication | Manager collects worker results | Direct messaging + broadcast between agents |
| Persistent goals | /goal: multi-day objectives, pause/resume | /goal: persistent work until condition met |
| Cross-session memory | Memories (configurable, off by default) | Auto-memory (saves project context) |
| Execution environment | Cloud (internet disabled for security) | Local machine (full access) |
Codex: Subagents GA (March 14, 2026)
A manager agent decomposes your task into subtasks and spawns explorer, worker, or default agents in parallel cloud sandboxes. Up to 8 agents run simultaneously. Each sandbox is isolated. The Symphony framework (open-source, Elixir-based) powers the orchestration internally.
Claude Code: Agent Teams + Agent View
Agent Teams let you spawn sub-agents that share a task list with dependency tracking, send messages to each other, and work in parallel on git worktrees. The new 'claude agents' command (v2.1.139) provides a dashboard to manage all running, blocked, and completed sessions in one view.
Dedicated Context Per Task
Both approaches validate the same insight: a dedicated context window per task is a lasting primitive. The question is whether you want isolated speed (Codex) or coordinated depth (Claude). For greenfield tasks that are independent of each other, Codex's isolation model wins. For complex refactors where subtasks have dependencies, Claude's coordinated teams win.
Claude Code: Agent Teams in Action
# Spawn a team for a complex feature
$ claude "Build the payment integration"
# Claude Code automatically:
# 1. Creates a team with task list
# 2. Spawns researcher agent → explores Stripe SDK patterns
# 3. Spawns implementer agent → writes the code (blocked until research done)
# 4. Spawns test-writer agent → writes tests in parallel
# Each agent has its own context window. No pollution.
# Agents message each other when done: "research complete, found 3 patterns"
# Task dependencies prevent implementer from starting before researcher finishesUsage Limits: What the Pricing Pages Leave Out
This is the section that will save you hundreds of dollars. The pricing pages don't tell you the real story about limits.
The Pricing Restructure (April 2026)
OpenAI restructured its tiers in April 2026. ChatGPT Pro now comes in $100/mo (5x Plus limits, GPT-5.5 Pro) and $200/mo (20x limits) variants. Anthropic's tiers remain $20 (Pro), $100 (Max 5x), and $200 (Max 20x). The $20 tier gap persists: ChatGPT Plus still gets more sessions per dollar than Claude Pro.
| Tier | Codex (ChatGPT) | Claude Code | Key Difference |
|---|---|---|---|
| $8/month | ChatGPT Go (limited) | N/A | Entry tier for Codex only |
| $20/month | Plus: GPT-5.5, Codex access | Pro: standard limits | Codex gets more sessions |
| $100/month | Pro: 5x Plus, GPT-5.5 Pro | Max 5x: 5x Pro usage | Both have $100 tiers now |
| $200/month | Pro: 20x limits | Max 20x: 20x Pro usage | Both generous at this tier |
The Tier Structure in June 2026
OpenAI now offers four tiers: $0 (Free), $8 (Go), $20 (Plus), $100 (Pro), and $200 (Pro). Anthropic offers three paid: $20 (Pro), $100 (Max 5x), and $200 (Max 20x). The big change from February is OpenAI splitting Pro into $100 and $200 variants, matching Anthropic's two-tier premium structure. Both platforms let you buy additional credits at API rates when you hit limits.
The real cost question in 2026 is not the subscription price, it's how many agent sessions you get. With subagent workflows, each agent team run burns through limits faster because you are running multiple context windows in parallel. Codex caps at 8 subagents per developer. Claude's Agent Teams have no hard cap but eat limits proportionally to the number of sub-agents spawned.
Token Economics Nobody Discusses
A data point that should concern Claude users: in identical benchmark tasks, Claude Code used 4x more tokens than Codex.
| Task | Codex Tokens | Claude Tokens | Ratio |
|---|---|---|---|
| Figma Plugin Build | 1,499,455 | 6,232,242 | 4.2x more |
| Scheduler App | 72,579 | 234,772 | 3.2x more |
| API Integration | ~180,000 | ~650,000 | 3.6x more |
Why Claude Uses More Tokens
Claude's higher token usage is not necessarily waste. It correlates with more thorough, deterministic outputs. Claude "thinks out loud" more, asks clarifying questions, and provides more detailed explanations. Whether this is valuable depends on your use case.
Claude Token Philosophy
More tokens = more context = more thorough. Claude prioritizes completeness over efficiency, which helps with complex refactoring but burns through limits faster.
Codex Token Philosophy
Fewer tokens = faster completion = lower cost. Codex prioritizes efficiency, which means faster results but potentially less thorough coverage of edge cases.
API Pricing Reality (May 2026)
If you are using the API directly (not the subscription), the pricing has shifted:
- Claude Opus 4.8 API: $5 input / $25 output per 1M tokens (same as Opus 4.7)
- Claude Sonnet 4.6 API: $3 input / $15 output per 1M tokens
- GPT-5.5: pricing varies, generally lower per-token than Claude Opus
Opus 4.8 brought an 8-point jump on SWE-bench Verified at the same API price as Opus 4.6. For agent team workloads where you are spawning multiple sub-agents, using Sonnet for worker agents and Opus 4.8 only for the lead agent can cut costs significantly. Opus 4.8 also introduced effort levels including "xhigh" (between high and max), letting you tune cost vs thoroughness per task.
The Configuration Tax: Setup Time Reality
Both tools have converged on features. Codex now has goals, memories, hooks, plugins, and vim mode. Claude Code now has the agent view dashboard, custom themes, effort levels, and /ultrareview. The configuration gap is narrower than in February.
Codex: What Changed Since February
- Subagents GA (March 14): manager-worker pattern, up to 8 parallel agents
- /goal command: persistent multi-day objectives with pause/resume (v0.128.0)
- Memories: cross-session context, git-backed workspace diffs (configurable)
- Vim mode in TUI composer with /vim command (v0.129.0)
- codex remote-control: headless app-server for CI/pipeline integration (v0.130.0)
- Chrome extension with parallel tab support (May 7)
- Mobile support via ChatGPT mobile + Codex App connection (May 14)
- Hooks GA: lifecycle hooks browsable from /hooks (v0.129.0)
- GPT-5.5 model support, GPT-5.4 for Bedrock
- Plugin marketplace with workspace sharing and remote bundles
- 91,000 GitHub stars, 800+ releases, Apache-2.0
Claude Code: What Changed Since February
- Opus 4.8 default (May 28): SWE-bench Verified 88.6%, Pro 69.2%, CursorBench 70%
- claude agents dashboard: unified view of all sessions (v2.1.139, May 11)
- /goal command: persistent work until completion condition met (v2.1.139)
- /ultrareview: parallel multi-agent cloud code review (v2.1.111)
- Effort levels: xhigh between high and max (v2.1.111, April 16)
- Auto mode available for Max subscribers without --enable flag
- Custom themes via /theme command (v2.1.118)
- Vim visual mode (v) and visual-line mode (V) (v2.1.118)
- Plugin ecosystem with marketplace, hooks, and MCP tool integration
- Push notifications via Remote Control (v2.1.110)
- PowerShell support on Windows (progressive rollout, v2.1.111)
- 132,000 GitHub stars, v2.1.176, proprietary
Anthropic's Cowork desktop app for Claude Code. Folder-based project management with task routing. Source: SemiAnalysis.
Configuration Cost
The configuration gap between these tools has narrowed. Both now support goals, memories, hooks, plugins, vim mode, and remote/headless operation. Codex ships AGENTS.md (similar to CLAUDE.md). The main remaining difference: Claude Code's hooks are more granular (PreToolUse, PostToolUse, PreCompact) while Codex's are lifecycle-scoped.
Claude Code: CLAUDE.md Example
# CLAUDE.md - Project-specific instructions
## Code Style
- Use TypeScript strict mode
- Prefer functional components
- No any types without explicit comment
## Architecture
- All API calls go through /lib/api
- State management via Zustand
- Never modify package.json without asking
## Testing
- Write tests before implementation (TDD)
- Minimum 80% coverage for new code
- Use React Testing Library patternsWith Claude Code, you can completely replace the system prompt. This is useful for creating specialized agents, but it is a time investment that Codex does not require.
Failure Mode Analysis: When Things Go Wrong
Both tools fail. Understanding HOW they fail tells you which failure mode you can tolerate.
Codex Failure Patterns
- Variability: Same prompt produces different results across runs
- Off-plan drift: Ignores instructions when "in the zone"
- Defensive over-engineering: Adds unnecessary error handling
- Style ignorance: Doesn't adapt to codebase patterns
- Context switching: Loses track in complex multi-file edits
- Multi-agent CSV fan-out: No mid-batch error recovery, one failure can stall the pipeline
- Security: zsh sandbox bypass fixed in v0.106.0, but raises questions about sandbox trust model
Community Signal
A "Codex is rapidly degrading" thread on the OpenAI community forum has been gaining traction. Multiple users report declining output quality over the past month. Worth monitoring if you are evaluating Codex for a long-term workflow.
Claude Code Failure Patterns
- Over-interruption: Asks permission too frequently (mitigated by auto-accept mode)
- Context window issues: Compaction hits after 5-6 prompts
- Limit walls: Stops mid-task when hitting caps
- Eager gap-filling: Makes assumptions without flagging them
- Token bloat: Verbose explanations eat into limits
For context on Claude Code's real-world reliability: Rakuten reported 99.9% numerical accuracy on a 12.5M-line codebase. At that scale, even small failure rates compound. The gap between Codex and Claude on consistency is measurable in production.
"Codex sometimes flags plausible edge-case database query concurrency bugs that I have to manually verify for 30 minutes, only to conclude they're hallucinations." (HN commenter)
The Recovery Question
When Codex fails, you typically need to re-prompt from scratch. When Claude fails, you can often guide it back on track through conversation. This makes Claude failures feel more recoverable, even if they happen more often due to limit issues.
The Context Window Problem: The Hidden Battleground
Claude Opus 4.7 ships with a 1M token context window. Codex stays at 200K tokens. But raw context size is only part of the story.
| Aspect | GPT-5.5 / Codex | Claude Opus 4.8 |
|---|---|---|
| Raw context window | 200K tokens | 1M tokens |
| Memory management | Diff-based forgetting + Memories MCP | Automatic compaction + auto-memory |
| Large file handling | Smooth up to 2000+ lines | Handles massive files with 1M context |
| Multi-agent context | Isolated per sandbox, 8 agent cap | Shared via team config + task list |
| Long session stability | Excellent with diff-based forgetting | Improved: compaction + /goal for persistent work |
| Effort control | Standard reasoning levels | xhigh effort level (between high/max) |
The context window gap widened with Opus 4.7 (1M vs 200K). But Codex compensates with diff-based forgetting and a new Memories MCP server (v0.129.0) that provides structured cross-session context with search, pagination, and line-offset reads. Claude Code's auto-memory and automatic compaction handle long sessions differently: summarizing old context instead of diffing it away. For a deep dive on why context rot degrades agent performance and how context compression techniques like FlashCompact address it, see our analysis.
Where Codex Wins
Terminal-Heavy Workflows
GPT-5.5 leads Terminal-Bench 2.0 at 82.7% vs Claude's 69.4%. If your workflow is terminal-native (DevOps, scripts, CLI tools), Codex is measurably better. Vim mode in the TUI composer makes it even more terminal-native.
Long Autonomous Sessions with Goals
The /goal command (v0.128.0) lets Codex schedule future work and wake up automatically to continue on long-term tasks, potentially across days or weeks. Combined with memories for cross-session context, Codex now handles truly persistent workflows.
Budget-Conscious Teams
ChatGPT Plus ($20) still gets more sessions than Claude Pro ($20). The $8 Go tier and new $100 Pro tier (5x Plus with GPT-5.5 Pro) give more price points than Claude's lineup.
SWE-bench Verified Accuracy
GPT-5.5 leads SWE-bench Verified at 88.7% vs Opus 4.8's 88.6%. The gap is 0.1 points — essentially tied on the most-cited coding benchmark as of June 2026.
Best For: Spec-Driven Parallel Workflows
If you write detailed specs and want to context-switch while the AI works, Codex is your tool. The Codex App (macOS + Windows), Chrome extension (May 7), and mobile access (May 14) make this workflow available everywhere. Subagents GA means you can spawn 8 parallel workers from a single task. The codex remote-control command (v0.130.0) enables headless operation for CI/pipeline integration.
Where Claude Code Wins
SWE-bench Pro Accuracy
Claude Opus 4.8 leads SWE-bench Pro at 69.2% vs GPT-5.5's 58.6%. That's a 10.6-point gap. For real-world codebase fixes, Claude has the edge.
Massive Codebase Navigation
With 1M token context and CursorBench at 70% (up from 58% on Opus 4.6), Claude handles large codebases better. Rakuten confirmed 99.9% accuracy on 12.5M lines.
Agent View Dashboard
The 'claude agents' command (v2.1.139) provides a single dashboard for all running, blocked, and completed sessions. Combined with /goal for persistent objectives and /ultrareview for parallel code review, Claude Code's session management is more sophisticated.
Custom Automation via Hooks
Claude Code's hooks are more granular: PreToolUse, PostToolUse, PreCompact, PostToolUseFailure with duration_ms, continueOnBlock, and MCP tool invocation. Build CI-like pipelines around your agent workflows with fine-grained lifecycle control.
Best For: Multi-Agent Orchestration
If you want to architect a solution and let a team of agents execute it in parallel, with dependency tracking, inter-agent messaging, and shared task lists, Claude Code's Agent Teams remain the strongest option. 16 Claude agents wrote a 100K-line C compiler in Rust that compiles the Linux kernel 6.9 (99% GCC torture test pass rate, ~$20K API cost). That proof point still stands. With Opus 4.8's 7.8-point jump on SWE-bench Verified and 13.8-point jump on SWE-bench Pro (vs Opus 4.6 baseline), the per-agent quality improved significantly at no price increase.
"For production coding, I create fairly strict plans. Codex goes off plan most of the time. Claude follows them.",HN commenter
Hybrid Workflow: Using Both
Power users figured this out early: these tools complement each other. The optimal workflow is not choosing one. It is knowing when to switch.
The Optimal Hybrid Flow
- Prototype with Codex: Fast iteration, explore multiple approaches
- Review with Claude: Code review, catch edge cases Codex missed
- Refactor with Claude: Complex architectural changes with deterministic outputs
- Final polish with Codex: Quick fixes and formatting
Power User Hybrid Workflow (May 2026)
# 1. Scaffold with Codex subagents in cloud sandbox
$ codex "Implement user authentication with JWT, following patterns in /lib/auth"
# Manager spawns explorer + worker agents in parallel sandboxes
# /goal keeps the task alive across sessions if needed
# 2. Orchestrate review + hardening with Claude Agent Teams
$ claude "Review the auth implementation. Spawn a security reviewer agent
and a test writer agent. Security reviewer checks for OWASP top 10.
Test writer creates integration tests. Block merge until both pass."
# claude agents dashboard shows all agents' status
# /ultrareview runs parallel multi-agent cloud code review
# 3. Quick fix with Codex
$ codex "Fix these 3 security issues: [paste Claude's findings]"
# Done in 2 minutes, cloud sandbox, no context pollutionCross-Tool Review
Several developers report using Codex specifically to review Claude's work. "I use Codex for review tasks. When working on something complex, I frequently ask Codex to review Claude's work, and it does a good job catching mistakes."
Decision Framework: Pick Your Tool in 30 Seconds
| Your Situation | Best Choice | Why |
|---|---|---|
| Multi-agent orchestration | Claude Code | Agent Teams with task deps + messaging + agent view |
| Parallel sandbox execution | Codex | Subagents GA: 8 parallel workers in cloud containers |
| Budget: $20/month | Codex | More sessions per dollar on ChatGPT Plus |
| SWE-bench Pro accuracy | Claude Code | 69.2% vs 58.6% (Opus 4.8 vs GPT-5.5) |
| Terminal-heavy workflows | Codex | 82.7% Terminal-Bench vs 69.4% Claude |
| Large codebase refactoring | Claude Code | 1M context + agent teams for divide-and-conquer |
| Persistent multi-day tasks | Codex | /goal with auto-wakeup, memories for cross-session context |
| Custom automation | Claude Code | Granular hooks (PreToolUse, PostToolUse, PreCompact) |
| Want open-source CLI | Codex | Apache-2.0, Rust-native, 91K stars |
| Max context window | Claude Code | 1M tokens vs 200K |
Frequently Asked Questions
Is Codex or Claude Code better for coding in 2026?
It depends on your workflow. GPT-5.5 leads Terminal-Bench 2.0 (82.7% vs 69.4%) and SWE-bench Verified by 0.1 point (88.7% vs 88.6%). Claude Opus 4.8 leads SWE-bench Pro (69.2% vs 58.6%) and CursorBench (70%). Claude Code authors ~10% of all public GitHub commits, roughly 326K per day, up from 4% in February. Codex shipped subagents GA in March with up to 8 parallel workers. The biggest differentiator is still subagent architecture: isolated manager-worker execution (Codex) vs coordinated sub-agents with messaging (Claude).
What are Claude Code Agent Teams?
Agent Teams let you spawn multiple sub-agents that each get a dedicated context window. They share a task list with dependency tracking and can message each other directly. Each agent works in a git worktree for isolation. In May 2026, Claude Code added the "claude agents" dashboard (v2.1.139) for managing all sessions, and the /goal command for persistent work until a completion condition is met. The /ultrareview command (v2.1.111) runs parallel multi-agent code reviews in the cloud.
What are Codex subagents?
Codex shipped subagents to GA on March 14, 2026. A manager agent decomposes your task into subtasks and spawns explorer, worker, or default agents in parallel cloud sandboxes. Up to 8 agents run simultaneously. The Symphony framework (open-source, Elixir-based) powers the orchestration. Combined with /goal for multi-day persistence and memories for cross-session context, Codex now handles genuinely complex long-running projects.
Which has better usage limits: Codex or Claude Code?
OpenAI restructured pricing in April 2026: Go ($8), Plus ($20), Pro $100 (5x Plus, GPT-5.5 Pro), and Pro $200 (20x limits). Anthropic offers Pro ($20), Max 5x ($100), and Max 20x ($200). ChatGPT Plus still gets more sessions per dollar at the $20 tier. Both offer overflow at API rates. Subagent workflows multiply limit consumption since each agent uses its own context window.
Can I use both Codex and Claude Code together?
Yes, and the hybrid workflow is increasingly common. Use Codex for rapid prototyping and subagent-parallel implementation in cloud sandboxes, then use Claude Code's Agent Teams for code review (/ultrareview), security auditing, and complex refactoring with coordinated agents.
Which is more open source?
Codex CLI is fully open-source under Apache-2.0, Rust-native, with 91,000+ GitHub stars and 800+ releases. Claude Code (132,000+ stars) ships more frequently with multiple releases per day but is a proprietary Anthropic product. Both tools' underlying models are proprietary. Both have active plugin ecosystems.
WarpGrep v2 Boosts Any Coding Agent on SWE-bench Pro
WarpGrep v2 adds 2-3 points on SWE-bench Pro to every model tested: Opus 4.6 from 55.4% to 57.5%, Codex from 57.0% to 59.1%. It works as an MCP server inside Claude Code, Codex, Cursor, and any tool that supports MCP. Better search = better context = better code.
Sources
- SemiAnalysis: Claude Code is the Inflection Point (Feb 5, 2026)
- Anthropic: Introducing Claude Opus 4.7 (April 16, 2026)
- Anthropic Engineering: Building a C Compiler with Claude Agents
- Claude Code Changelog (v2.1.185, June 20, 2026)
- OpenAI Codex CLI Releases (v0.139.0, June 9, 2026)
- OpenAI Codex Subagents Documentation
- OpenAI Codex Changelog (May 2026)
- Terminal-Bench 2.0 Leaderboard
- Scale AI SWE-Bench Pro Leaderboard
- CoreMention: Claude Code 326K+ Daily Commits Tracker
- OpenAI Codex Pricing Documentation
- Claude Code vs Cursor: Full Comparison