A large language model writes one token at a time, and each token waits on loading the whole model from memory, not on math. Speculative decoding fills that idle time. A small, fast model guesses the next chunk of tokens, the big model checks the whole guess in one pass, and keeps every token it got right. The output is identical to the big model alone, just 2-3x faster.
The Short Answer
Speculative decoding speeds up an LLM by letting a small, fast model guess several tokens ahead, then having the large model check all of those guesses at once. The large model still decides every token, so the text it produces is exactly what you would have gotten without the trick. You just get it 2-3x faster because checking a batch of guesses costs about the same as generating a single token.
That last part sounds backwards, so the rest of this page explains why it is true.
Why One Token at a Time Is Slow
To produce a single token, a model runs a full forward pass over all of its weights. The surprising part is where the time goes. Almost all of it is spent loading those weights out of memory and into the GPU's compute cores. The actual matrix math is fast. The model is bottlenecked on memory bandwidth, not on arithmetic.
One consequence is that the compute cores sit mostly idle on every step, waiting for weights to arrive. Another is that checking a few extra tokens in the same pass is nearly free: the weights are already loaded, so you might as well run more numbers through them. Speculative decoding is built entirely on this second fact.
Generating a token is slow because of memory, not math. So verifying a batch of guessed tokens in one pass costs about the same as generating one token. That gap is the free speed speculative decoding harvests.
Guess Ahead, Then Check
There are two models. A small draft model is fast but not as good. The large target model is the one whose output you actually want. The draft proposes a short run of guessed tokens, which is cheap because it is small. The target then checks all of those guesses in a single forward pass.
Picture a fast typist and a careful editor. The typist guesses the next few words of a sentence. The editor reads the whole guess in one glance and keeps everything up to the first word they would have written differently. Everything before that point was right, so it stays. The editor fixes the first wrong word, and the typist guesses again from there. The editor never lowers the quality of the writing, but a lot of the typing got done by someone faster.
How It Works, Step by Step
One round of speculative decoding does four things:
- Guess. The draft model proposes K candidate tokens, one after another. This is cheap because the draft is small.
- Check. The target model runs one forward pass over all K candidates at once and records what it would have chosen at each position.
- Accept. Compare the guesses to the target's choices left to right. Keep every token that matches, stop at the first one that does not.
- Correct and repeat. Replace the first wrong guess with the target's own token, then start the next round from there.
A concrete round: the draft guesses 5 tokens, the target accepts the first 3, rejects the 4th. Those 3 tokens cost one target forward pass instead of three. The 4th becomes the target's own token, and the next round guesses forward from there. Over many rounds, the average number of tokens accepted per pass is what sets the speedup.
If the target accepts an average of 3 tokens per verification pass, it produces roughly 3 tokens for the cost of 1, plus the cheap draft work. That is where a 2-3x speedup comes from. Accept more per pass and you go faster; accept fewer and the gain shrinks.
Why It Doesn't Change the Output
The verification step is not a guess about quality. The target model only accepts a token when it matches what the target itself would have produced, and the accept/reject rule uses a modified rejection sampling scheme that provably preserves the target's output distribution. The text you get is statistically identical to running the target model alone.
This is the property that makes it safe to ship. Quantization, distillation, and pruning all trade a little quality for speed. Speculative decoding does not. It needs no retraining and no changes to the model. You pair an existing model with a draft and get the same output, faster. It is the same guarantee no matter where the draft comes from.
What Makes It Faster or Slower
One number controls everything: the acceptance rate, the fraction of guessed tokens the target keeps before the first mismatch. High acceptance means many free tokens per pass and a large speedup. Low acceptance means the draft work was wasted, and a bad enough draft can make the whole system slower than plain decoding.
Three things push acceptance up. The draft should be much smaller than the target, so guessing stays cheap. The task should be input-grounded, where the next tokens are predictable from the input. And sampling should be greedy or low-temperature, because high temperature makes the target's choices less predictable and rejects more guesses.
| Where the guess comes from | Typical speedup | Best for |
|---|---|---|
| Separate small draft model | Under 2x | General text |
| Draft tuned to your workload | Over 3x | A specific task like code |
| Heads or features on the target | ~2-3x | No second model to run |
A better draft gets more of its guesses accepted, so each verification pass commits more tokens. More accepted, fewer target passes, faster output. The text is identical either way.
Code is the standout. When a model edits a file, most of the output is unchanged lines that already exist in the input, so the next tokens are easy to predict and a high fraction of guesses get accepted. That is why the biggest speedups in practice show up on code.
The Variants In Practice
Speculative decoding has grown into a family of methods. They mostly differ in one thing: where the draft comes from. The original approach pairs the target with a separate small model. Later work moved the draft inside the target so there is no second model to run.
A second, smaller model proposes the tokens. The original approach.
Medusa adds lightweight prediction heads to the target. No second model.
EAGLE drafts from the target's own internal features, then converts them to tokens.
That is the idea in the abstract. It is worth seeing how the papers themselves draw it, because the diagrams make the draft-then-verify loop concrete.
DSpark (DeepSeek, June 2026) is a good recent example, and its figure maps almost exactly onto the animation at the top of this page. A parallel backbone drafts a run of tokens; a confidence-aware scheduler keeps the part likely to survive and drops the rest; the target verifies what is left in one pass and corrects the first miss.

DSpark's decoding cycle. A parallel backbone plus a lightweight sequential head draft tokens E to H with confidence scores; a hardware-aware scheduler keeps the confident prefix (E, F, G) and drops H; the target verifies in parallel, accepting E and F and correcting G. The same draft-then-verify loop, with a smarter scheduler deciding how much to verify.
Medusa takes the no-second-model route: it bolts extra decoding heads onto the target to propose several tokens at once, then verifies the candidates with tree attention.

Medusa adds extra decoding heads on top of the target model to predict several future tokens at once, then verifies the candidate continuations with tree attention. No separate draft model to train or serve.
EAGLE drafts from the target's own internal features instead of its tokens, which raises the acceptance rate. The payoff is measured in accepted tokens per pass, and it compounds into real speedups.
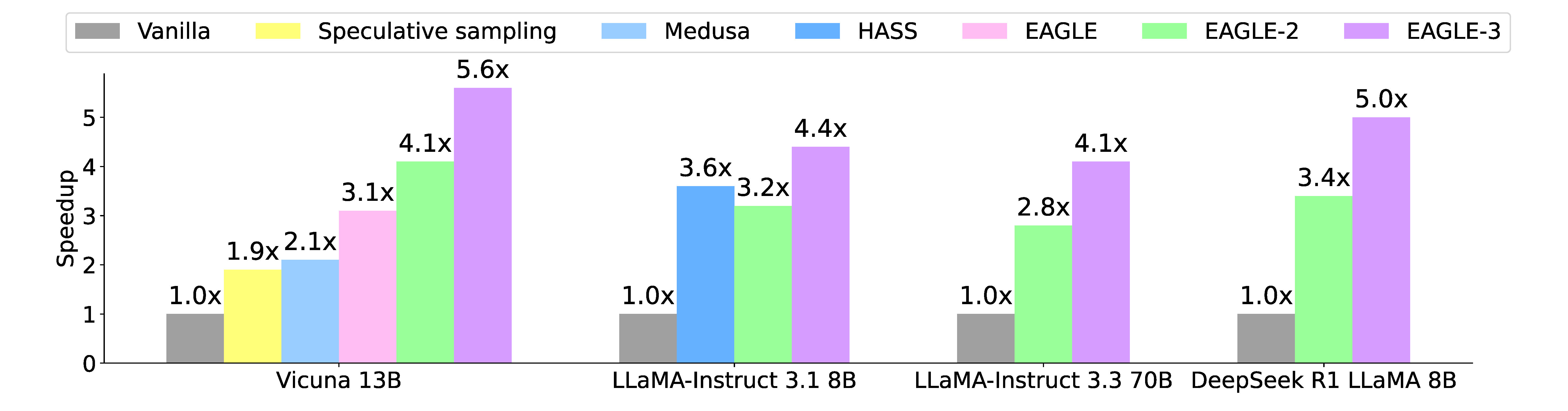
EAGLE-3 measured speedups over vanilla decoding across models and tasks. Drafting at the feature level keeps more tokens accepted per pass than earlier methods, which is what turns into end-to-end speed.
How Morph Uses It
Morph's Fast Apply model merges an AI-suggested edit into a file. Most of the next tokens are unchanged lines already sitting in the original code, so the model is mostly copying code it can already see. That keeps the acceptance rate high.
With speculative decoding tuned to that workload, morph-v3-fast serves at ~10,500 tok/s and the compactor at ~33,000 tok/s, with output identical to plain decoding.
This page is the plain-language tour. For the rejection-sampling proof, the EAGLE and Medusa variants, the published speedup tables, and the exact production numbers, read Speculative Decoding: How Draft Models Multiply LLM Inference Speed.
Frequently Asked Questions
How does speculative decoding work in simple terms?
A small, fast model guesses the next several tokens. The large model checks all of those guesses in a single forward pass and accepts them left to right until the first one it disagrees with. Accepted tokens are nearly free, because that pass would have produced just one token anyway. The first mismatch stops the run, the large model supplies the correct token, and the next guess starts there. The output is the same text the large model would have produced alone, 2-3x faster.
Does speculative decoding make the model less accurate?
No. The large model decides every token and only accepts a guess that matches what it would have generated on its own. The verification provably preserves the large model's output distribution, so the text is statistically identical to running it with no draft. It is a speed optimization, not a quality tradeoff, and it needs no retraining.
How much faster is speculative decoding?
Typically 2-3x for a well-matched draft and target. The figure tracks the acceptance rate. A generic small draft gives under 2x; a draft tuned to the workload can exceed 3x. The gains are largest on input-grounded tasks like code editing, where the next tokens are easy to predict from the input.
Does speculative decoding need a second model?
Not always. The original method pairs the target with a separate small draft model, but other variants skip the second model. Medusa adds lightweight prediction heads to the target; EAGLE drafts from features inside the target itself. The draft only has to be cheaper than the target and agree with it often enough.
Why is it especially good for code?
Editing a file mostly copies unchanged lines that already exist in the input, so the next tokens are highly predictable and a high fraction of guesses are accepted. Morph serves morph-v3-fast at ~10,500 tok/s with speculative decoding tuned to that workload, with output identical to plain decoding.
Apply edits at 10,500 tok/s
Morph Fast Apply merges AI-generated edits into your files with speculative decoding tuned to code. Same output, faster.